Contents
AC1.1. Plan for the collection of Secondary Data 2
AC1.2. Sample Methodology Including the Sampling Frame 3
AC 2.2. For the Mean Median and Mode 9
AC 2.3 Range, Standard Deviation, Lower quartile, Upper quartile, and the Inter-quartile range 9
AC 2.4 The Correlation Co-efficient for Temperature against Sales 11
AC 3.1 and AC 4.1 Line and Bar Graphs 13
AC 4.2. Project Duration and the Critical Path 17
4.3. Payback, the Net Present Value, and Internal Rate of Return 19
LO1: Be able to use a variety of sources for the collection of data, both primary and secondary
Scenario: You work as a research consultant and have been approached by a client. The client wishes to launch a new brand of trainers in London. However, before a budget is made available for business setup, the investors wish to conduct research to understand the market and market dynamics.
The products available under the new brand will all be based on unique designs (based on designs from graffiti artists) and will target both men and women of all ages.
Requirement: In a report to the Board of Directors provide the following:
The client wants to introduce a new brand of trainers in London and wishes to understand the market and market dynamics. As a result, it is important that data be collected in London, which will facilitate the research process. This owes to the reality that data collection is a crucial stage in the research process because failure to collect accurate data would result in misleading decisions. Specifically, a researcher could have an excellent research design, but may not be able to obtain credible evidence from the data if it is inaccurate. Critical to the discussion is the fact data could be collected from either primary sources or secondary sources. It follows that all the sources of data will be used to collect data for the research under discussion. Specifically, secondary sources of data will help the researcher to develop a questionnaire, which will in turn be used to collect data from the population in London.
It is evident that the research process will begin by collection of secondary data. To begin with, the population of London will be obtained from secondary sources because the information will be useful in calculating the sample size for the research. After identifying the population size, the researcher will retrieve information that could help in designing the questionnaire from other secondary sources. Specifically, information that will be collected from secondary sources includes types of sneakers in London, and characteristics of types of sneakers in the City. The information will be extracted from the secondary sources and tabulated with an aim of identifying trainers and characteristics that could be grouped together. The result obtained will then be used to design a questionnaire that will then be used to collect date directly from the population. This reveals that data from secondary source will have a crucial role in the research process.
After designing the questionnaire, a sample size will be calculated and questionnaires will be prepared depending on the size of the resulting sample. Data collectors, who will help in collecting data, will be selected based on their qualifications. The data will be collected from wards within the city implying every ward will have a different sample size. Each data collector will be sent to their ward with a set of questionnaires for collecting data. Critical to the discussion to the discussion is the fact that the researcher will ensure every data collector has extra questionnaires because some of the questionnaires could be spoilt when they are collecting data. Further, all the data collectors will be trained on data collection techniques that are specific to the research. After the data is collected, it will be extracted from questionnaires and tabulated on a spreadsheet where it will be cleaned in preparation for analysis.
As mentioned before, simple random sampling will be used to select the study participants. All wards in London were listed down and their respective population sizes collected from secondary sources. The sample size for every data collector was collected based on the populations in the region below (the sampling frame).
| Region | Size | Region | Size | Region | Size |
| City of London | 8211 | Hackney | 265317 | Newham | 332600 |
| Barking & Dagenham | 203623 | Hammersmith & Fulham | 181734 | Redbridge | 297469 |
| Barnet | 383036 | Haringey | 270955 | Richmond upon Thames | 196175 |
| Bexley | 240577 | Harrow | 249832 | Southwark | 306734 |
| Brent | 325266 | Havering | 247714 | Sutton | 201211 |
| Bromley | 324575 | Hillingdon | 296490 | Tower Hamlets | 287078 |
| Camden | 237341 | Hounslow | 271846 | Waltham Forest | 273940 |
| Croydon | 380769 | Islington | 224564 | Wandsworth | 317998 |
| Ealing | 349738 | Kensington and Chelsea | 156086 | Westminster | 235050 |
| Enfield | 329059 | Kingston upon Thames | 170895 | Lewisham | 294095 |
| Greenwich | 273001 | Lambeth | 322008 | Merton | 208433 |
It is important to highlight that the sample sizes were calculated using the formula;
(Bartlett, E. J., Kotrlik, W. J., and Higgins 2001)
Consequently, the sample size for each region was obtained as shown below. The data collectors were required to collect data from residents in the city. Consequently, the moved from one resident to another obtaining addresses, locations, and contact addresses for London residents. The data was then tabulated in Excel and a unique identifier given to every resident. The software was then used to randomly select the study participants using the function RAND () (Ajay, Micah, 2014). The selected members were contacted and requested to help in the research by filling in questionnaires. It is critical to note that every study participant preferred to respond to the questionnaire differently. Consequently, some questionnaires were sent to the study participants via mail who responded to the questionnaires and sent back their responses. Some study participants preferred to participate in the study through telephone interviews.
| Region Sample | Size | Region Sample | Size | Region Sample | Size |
| City of London | 367 | Hackney | 384 | Lewisham | 384 |
| Barking & Dagenham | 383 | Hammersmith & Fulham | 383 | Merton | 383 |
| Barnet | 384 | Haringey | 384 | Newham | 384 |
| Bexley | 384 | Harrow | 384 | Redbridge | 384 |
| Brent | 384 | Havering | 384 | Richmond upon Thames | 383 |
| Bromley | 384 | Hillingdon | 384 | Southwark | 384 |
| Camden | 384 | Hounslow | 384 | Sutton | 383 |
| Croydon | 384 | Islington | 384 | Tower Hamlets | 384 |
| Ealing | 384 | Kensington and Chelsea | 383 | Waltham Forest | 384 |
| Enfield | 384 | Kingston upon Thames | 383 | Wandsworth | 384 |
| Greenwich | 384 | Lambeth | 384 | Westminster | 384 |
AC1.3. Sample Questionnaire
I am a researcher from XYZ Inc. Our organization is conducting a research on the market dynamic and tastes from the market on trainers. Consequently, I would wish to seek your assistance in responding to the following questions. You are supposed to provide your responses in the spaces provided.
What is your gender?
Male Female
Do you have a set of trainers?
Yes No
Indicate the type of trainers you have by ticking in the check box provided
White Mountaineering Skora Running
Alejandro Ingelmo New Balance
Clae Visvim
What is your shoe size?
Do you prefer light colored trainers or dark colored trainers?
I prefer light colored trainers
I prefer dark colored trainers
LO2: Understand a range of techniques to analyze data effectively for business purposes
Scenario: Karen; the owner of a small café based in London has realized the importance of analyzing the sales for the purpose of decision-making.
Karen has collected the following data over the last month and has requested you to help her with further analysis (use of various statistical techniques).
The following table presents the number of orders within different price ranges:
| AmountSpent (£) | No. ofOrders |
| 0 – 10 | 5 |
| 10 – 20 | 7 |
| 20 – 30 | 10 |
| 30 – 40 | 12 |
| 40 – 50 | 14 |
| 50 – 60 | 15 |
| 60 – 70 | 14 |
| 70 – 80 | 13 |
| 80 – 90 | 6 |
| 90 -100 | 4 |
You are required to calculate the following (covers AC 2.1):
It is notable that the data provided is grouped implying finding its mean mode, and median could be challenging. In order to obtain the mean we find the midpoints for the classes, which is obtained by taking the upper class boundary plus the lower class boundary and divide the result by two. For example to obtain the midpoint for the 0-10 class take;
Midpoint = (0+10)/2. The procedure was repeated for all the classes and the results were tabulated in the column labeled midpoints in the table below. The midpoint was then multiplied by the frequency and the result tabulated in the column labeled Freq*midpoint in the table below.
The totals for the Freq column and the Freq*midpoint column was than obtained. As a result, the mean was obtained by dividing the sum of Freq*midpoint by the sum of the frequencies.
Mean = 5030/200
= 50.30
| Amount Spent | Freq | Midpoints | Freq*midpoint | Cumulative Frequency | Freq*midpoint^2 |
| 0 – 10 | 5 | 5 | 25 | 5 | 125 |
| 10 – 20 | 7 | 15 | 105 | 12 | 1575 |
| 20 – 30 | 10 | 25 | 250 | 22 | 6250 |
| 30 – 40 | 12 | 35 | 420 | 34 | 14700 |
| 40 – 50 | 14 | 45 | 630 | 48 | 28350 |
| 50 – 60 | 15 | 55 | 825 | 63 | 45375 |
| 60 – 70 | 14 | 65 | 910 | 77 | 59150 |
| 70 – 80 | 13 | 75 | 975 | 90 | 73125 |
| 80 – 90 | 6 | 85 | 510 | 96 | 43350 |
| 90 – 100 | 4 | 95 | 380 | 100 | 36100 |
| 100 | 5030 | 308100 |
In order to obtain the mode, the cumulative frequency for the prices was obtained by summing all the prices progressively. The results for the cumulative frequencies are tabulated in the column labeled cumulative frequency in the table above. The following formula was then used to obtain the mode from the data.
Mode = L +fm-fm-1fm-fm-1+fm-fm+1*w (Healey, 2012)
Where, L is the lower class boundary for the modal group, fm-1 is the frequency preceding the modal group, fm is the frequency containing the modal group, and fm+1 is the frequency proceeding the modal group, and w is the class width. Critical to the discussion is the fact that the modal group is the class containing the highest frequency. From the table above, the modal group (fm) is 50 – 60. It follows that fm+1 is given as the 60 -70 class, while fm-1 is the 40-50 class. Therefore, the mode for the prices is given as; Mode =49.5+(15-1415-14+(15-14))*10 . The answer from the calculation is 54.5, which is the mode.
It is important to highlight that the median for the data was obtained in a similar fashion as the mode. Critical to the discussion is the fact that the median is obtained by finding the average between the 50th and the 51st observation, which is in the 50-60 class. Further, the following formula was used to obtain the median.
Median = L+n2-BG*W (Healey, 2012)
Where, L is the lower class boundary for the median class, n is the total number of observations, B is the cumulative frequency for the groups before the median group, G is the frequency for the median class, and W is the class width. From the table above, it can be deduced that L is given as 49.5, n is given as 100, B is given as 48, G is given as 15, and W is given as 10. Replacing the values in equation 2 above;Median = 49.5+1002-4815*10, which gives the median as 50.83.
From the above calculations, the mean for the data is 50.30, the mode for the data is 54.5, and the median is 50.83. This indicates that most prices are around 50.30 while the middle price for the data is around 50.83. Therefore, Karen should price most of her products at around 54.5 because the mode indicates the price that is bought most frequently.
Calculate the following (using the above table) (covers AC 2.3):
The range for the data is obtained by taking the upper class boundary of the first interval – the lower class boundary of the first interval. Specifically, the range for the data is given as 99.5-0.5 = 99. The standard deviation for the data was calculated by first finding the variance using the following formula.
Standard deviation = (fx2-(fx)2nn-1 (Bird, 2013)
The midpoint was squared and multiplied by its adjacent observation to obtain the values that are tabulated in the column labeled Freq*midpoint^2 in the table above. The sum of Freq*midpoint^2 was then obtained by adding all the respective values, which gave the result 308,100. The total for the freq*midpoint was also obtained and squared than divided by 100, which gave the result 253009. Replacing the values in equation, three above resulted in the following equation.
Standard deviation = 308,100-25300999
This gave the standard deviation as 23.59.
It is important to highlight that the first quartile for the data was obtained in a similar fashion as the mode. Critical to the discussion is the fact that the first quartile is obtained by finding the average between the 25th and the 26th observation, which is in the 30-40 class. Further, the following formula was used to obtain the median.
First quartile = LQ1+n4-BG*W (Healey, 2012)
Where, LQ1 is the lower class boundary for the first quartile class, n is the total number of observations, B is the cumulative frequency for the groups before the first quartile class, G is the frequency for the first quartile class, and W is the class width. From the table above, it can be deduced that L is given as 29.5, n is given as 100, B is given as 22, G is given as 15, and W is given as 10. Replacing the values in equation 2 above;Median = 29.5+1004-2212*10, which gives the first quartile as 32.00.
The third quartile for the data was obtained in a similar fashion as the first quartile. Critical to the discussion is the fact that the first quartile is obtained by finding the average between the 75th and the 76th observation, which is in the 60-70 class. Further, the following formula was used to obtain the median.
Third quartile= LQ3+n4-BG*W (Healey, 2012)
Where, LQ3 is the lower class boundary for the third quartile class, n is the total number of observations, B is the cumulative frequency for the groups before the third quartile class, G is the frequency for the third quartile class, and W is the class width. From the table above, it can be deduced that LQ3 is given as 59.5, n is given as 100, B is given as 63, G is given as 14, and W is given as 10. Replacing the values in equation 2 above; Median = 59.5+1004-6314*10, which gives the first quartile as 40.93.
Consequently, the interquartile range was obtained by taking the first quartile from the third quartile. i.e 40.93-32.00 = 8.93.
Karen has also provided you with the following data:
| Sales VS Temperature | |
| 22o | £325 |
| 26o | £416 |
| 13o | £197 |
| 19o | £264 |
| 11o | £175 |
| 17o | £248 |
| 27o | £435 |
In addition, explain how quartiles, percentiles, and the correlation coefficient are used to draw useful conclusions in business
The Correlation Co-efficient was obtained using the following formula.
r=nxy-xy(nx2-(x)2)*(ny2-(y)2) (Boslaugh, 2012)
Where n=7 is the sample size, x is sales, and y is the temperature.
The values were calculated individually and tabulated as shown in the table below.
| Temperature | Sales | XY | X2 | Y2 |
| 22 | 325 | 7150 | 484 | 105625 |
| 26 | 416 | 10816 | 676 | 173056 |
| 13 | 197 | 2561 | 169 | 38809 |
| 19 | 264 | 5016 | 361 | 69696 |
| 11 | 175 | 1925 | 121 | 30625 |
| 17 | 248 | 4216 | 289 | 61504 |
| 27 | 435 | 11745 | 729 | 189225 |
| Totals 135 | 2060 | 43429 | 2829 | 668540 |
Replacing values from the table above into equation four above
r=7*43429-135*2060(7*2829-135^2)*(7*668540-2060^2)
This gives the correlation coefficient as 0.9873
The correlation coefficient is used to examine the existence of relationships between variables. A positive correlation coefficient implies a strong positive relationship between the variables in question while a negative correlation coefficient implies a negative relationship between the variables. Critical to the discussion is the fact that a value close to one implies a strong relationship while a value close to zero implies a weak relationship. It follows that there is a strong positive relationship between sales and temperature. Simply, Karen should increase her products when the temperature increases. Quartiles and percentiles are used in business decisions to set and identify targets. For instance, in the above example, Karen can tell that twenty-five percent of the products are priced below $32 while 75 percent of the products are priced below$40.93.
LO3: Be able to produce information in appropriate formats for decision making in an organizational context.
Scenario: You work as a management consultant for Omega Consultants Limited. The company has provided you with the following information:
Year | Sales (£’000) – All Regions | All Costs – (Directand Indirect)(£’000) | FinalProfit(£’000) |
| 2000 | 170 | 140 | 30 |
| 2001 | 190 | 130 | 60 |
| 2002 | 230 | 150 | 80 |
| 2003 | 240 | 150 | 90 |
| 2004 | 320 | 180 | 140 |
| 2005 | 340 | 180 | 160 |
| 2006 | 270 | 170 | 100 |
| 2007 | 250 | 150 | 100 |
| 2008 | 250 | 180 | 70 |
| 2009 | 260 | 160 | 100 |
| 2010 | 300 | 160 | 140 |
Requirement: You are required to produce:
The data above was tabulated in Microsoft Excel, which was used to produce bar graphs and line graphs as the researcher deemed appropriate. From the line graph in figure 1 below it can be deduced that profits increased gradually from the year 2000 to 2005 before dropping gradually in 2008 and increased thereafter (McCullough, and Heiser, 2008). Analogously, the bar graph on figure 2 below indicates that the organization spend more money to make less profits in 2000 than in 2005. Thus, it could be deduced that the company makes good profits if it lowers the cost of business.
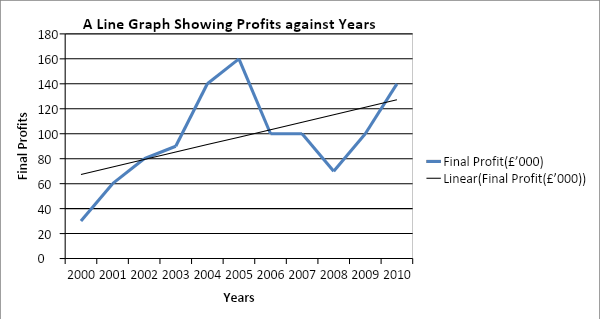
Figure 1: A line graph showing final profits against years

Figure 2: A bar graph showing sales, costs, and final profits against years
From figure 1 above, the trend line indicates that the organization has, in general increased its profits from 2000 to 2010. Further, it can be deduce that there is a weak positive relationship between sales and years because the trend line increases steadily. It is also crucial to highlight that an R2 of 0.271 implies that 27.1 percent of the variation in profits could be explained by the increases in years. Above all, the profits could be predicted by the equation;
Final profits = 6*year + 61.273.
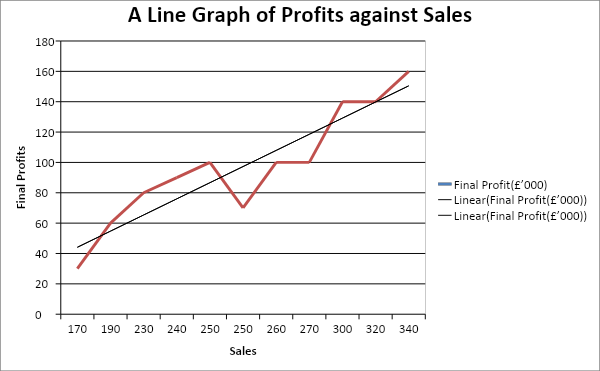
Figure 3: A line graph of final profits against sales
From figure 3 above, the trend line indicates that the organization increases its profits if the sales increase. Further, it can be deduced that there is a strong positive relationship between sales and profits because the trend line increases steadily. It is also crucial to highlight that an R2 of 0.8513 implies that 85.13 percent of the variation in profits could be explained by the increases in sales. Above all, the profits could be predicted by the equation;
Final profits = 10.636*sales + 33.455.
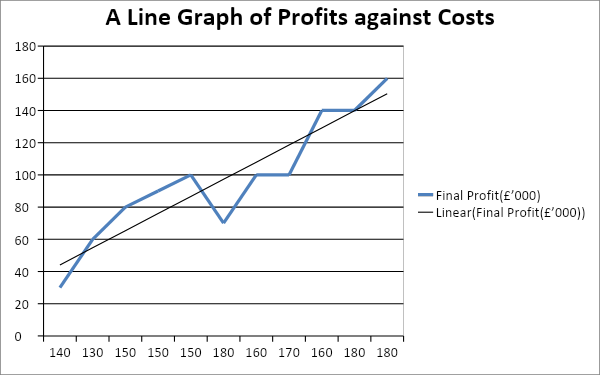
Figure 4: A line graph of profits against costs
From figure 4 above, the trend line indicates that the organization increases its profits if the costs increase. Further, it can be deduced that there is a strong positive relationship between costs and profits because the trend line increases steadily. It is also crucial to highlight that an R2 of 0.8513 implies that 85.13 percent of the variation in profits could be explained by the increases in costs. Above all, the profits could be predicted by the equation;
Final profits = 10.636*Costs + 33.455. Apparently, it can be deduced that sales and costs have the same effect on the final profits.
LO4: Be able to use software-generated information to make decisions in an organization
Scenario: You work as a project manager for Ace Investments Limited. The senior manager has provided you with the following information (related to a new project):
| Description | Activity | Preceding Activity | (Days) |
| Preparation | A | – | 4 |
| Business Planning | B | A | 2 |
| Recruitment and Selection | C | A | 36 |
| Installation of peripherals | D | B | 15 |
| Initial Training | E | D | 4 |
| Design | F | E | 9 |
| Conversion | G | F | 9 |
| Development of Norms | H | C | 2 |
| Assessment | I | B | 10 |
| Continuous Testing | J | D | 9 |
| Policy documentation | K | G,H,I,J | 20 |
| Appraisal | L | K | 20 |
Requirement (covers AC 4.2):
In order to determine the project’s duration, we develop the diagram shown in figure five below. The diagram was drawn by first obtaining the early starts and early finishes by adding activities duration to its early start. The numbers in the upper semicircle from the diagram below indicate the early start and finishes (Stelth, 2009). For example, an early start for activity A is zero and the activity has an early finish of four days. Proceeding to activity B, we take the duration for activity B, and add to it the early finish from activity A, which gives an early finish of six days. The procedure is repeated for all the activities up to the last activity, which is L. However, it is important to note that if an activity depends on the completion of two or more activities, its early start is obtained by taking the highest early finish from the previous activities (Morovatdar, Aghaie, Roghanian, Hadda, 2013). For example, activity K depends on activity G, J, I, and H. Therefore, we take the highest early finish from G, J, I, and H and use it as an early start for activity K. this owes to the reality that activity K can only begin if activities G, J, I, and H are complete. Using this procedure all the way to L, we obtain a project duration of 83 days.

In order to obtain the critical path, the late starts and late finishes were calculated by working backwards from the project’s duration. This was done by subtracting the projects duration from the early finish. For example, subtracting 20 from 83 obtained the late finish for activity K, which gave 63 days. However, it is important to note that if an activity depends on the completion of two or more activities; its early finish is obtained by taking the highest late start from the previous activities (Morovatdar, Aghaie, Roghanian, Hadda, 2013). For example, activity K depends on activity G, J, I, and H. Therefore, we take the highest late finish from K, and use it as a late start for activity G, J, H, and I. After working all the way through to activity A, the critical path is obtained by finding the path with equal late starts and early finishes. In this case, the critical path was obtained as A, B, D, E, F, G, K, and L.
LO4: Be able to use software-generated information to make decisions in an organization
Scenario: The Board members of a local construction company are planning to invest in a new project. The company has the option to select from two project; Project Super and Project Sonic.
You have been approached by the Board members to help them with the appraisal of both projects provide them with recommendations.
The following data is provided:
| Year | Project Super Cash flow (£) | Project Sonic Cash flow (£) |
| Investment | -200,000 | -200,000 |
| 1 | 35,000 | 218,000 |
| 2 | 80,000 | 10,000 |
| 3 | 90,000 | 10,000 |
| 4 | 75,000 | 4,000 |
| 5 | 20,000 | 3,000 |
Requirement:
The provided information does not have the interest on capital. This could be calculated from the current interest on government bonds, but the interest was assumed to be 12 percent for simplicity (Jiambalvo, 2009). The following formula was used to calculate the payback period in Microsoft Excel.
Payback period = No. of years before first positive cumulative cash flow + (Absolute value of last negative cumulative cash flow / Cash flow in the year of first positive cumulative cash flow) (Mayes, 2014).
Consequently, the payback period for project super was obtained as
Payback period = 3+((12/205000)*5000)
While the payback period for project sonic was obtained as
Payback= =0+((12/218000)*18000)
Consequently, the result was obtained as 3.292682927 years and 0.990825688 years for projects super and sonic respectively.
The net present values for the investments were obtained by using the NPV function in excel (Lasher, 2014). Specifically the function was entered as NPV (I3, B3:B7) +B2 for investment super and NPV (I3, C3:C7) +C2 for investment sonic. Similarly, the function IRR was used to obtain the internal rate of return in Microsoft Excel (Mayes, 2014). Specifically the function was entered as IRR(B2:B7,I3) for investment super and IRR(C2:C7,J3) for investment sonic. The table below could help understand how the functions were used. Consequently, the present values are obtained as $18,098.13 and $13,976.95. It is crucial to highlight that cell l3 which is not depicted in the table below contained the discounting factor.
| A | B | C | |
| 1 | Year | Project Super | Project Sonic |
| 2 | Investment | $ (200,000.00) | $ (200,000.00) |
| 3 | 1 | $ 35,000.00 | $ 218,000.00 |
| 4 | 2 | $ 80,000.00 | $ 10,000.00 |
| 5 | 3 | $ 90,000.00 | $ 10,000.00 |
| 6 | 4 | $ 75,000.00 | $ 4,000.00 |
| 7 | 5 | $ 20,000.00 | $ 3,000.00 |
| 8 | Net Present Value | $ 18,098.13 | $ 13,976.95 |
| 9 | Internal Rate of Return | 15.61882% | 18.71081% |
From the analysis above it is clear that both investments result in positive net present values implying they are both viable. However, project super has a higher net present value than project sonic implying the organization should invest in project sonic.
References
Ajay, S, S., Micah, B. M., 2014, Sampling Techniques and Determination of Sample Size in
Applied Statistics Research: An Overview. International Journal of Economics, Commerce, and Management, 2(11): 1-22.
Bartlett, E. J., Kotrlik, W. J., and Higgins, C. C., 2001, Organizational Research: Determining
Appropriate Sample Size in Survey Research. Information Technology, Learning and Performance Journal, 19(1): 43- 50.
Bird, J. 2013, Understanding Engineering Mathematics. Hoboken, N.J., Wiley.
Boslaugh, S. 2012, Statistics in a nutshell. Sebastopol, CA, O’Reilly Media.
Healey, J. F. 2012, Statistics: a tool for social research. Belmont, CA, Wadsworth, Cengage
Learning.
Jiambalvo, J. 2009, Managerial accounting. Hoboken, N.J., Wiley.
Lasher, W. 2014, Practical financial management. Mason, OH, USA: South-Western Cengage
Learning
Mayes, T., 2014, Financial Analysis with Microsoft Excel. New York, NW: Cengage Learning.
McCullough, B. D., and Heiser, A. D., 2008, On the accuracy of statistical procedures in
Microsoft Excel 2007. Computational Statistics and Data Analysis, 52: 4570-4578.
Morovatdar, R., Aghaie, A., Roghanian, E., Hadda, A., 2013, An Algorithm to Obtain Possibly
Critical Paths in Imprecise Project Networks. Iranian Journal of Operations Research, 4(1): 39-54.
Stelth, P., 2009, Projects’ Analysis through CPM (Critical Path Method). School of Doctoral Studies (European Union) Journal, 1: 11-4
Delivering a high-quality product at a reasonable price is not enough anymore.
That’s why we have developed 5 beneficial guarantees that will make your experience with our service enjoyable, easy, and safe.
You have to be 100% sure of the quality of your product to give a money-back guarantee. This describes us perfectly. Make sure that this guarantee is totally transparent.
Read moreEach paper is composed from scratch, according to your instructions. It is then checked by our plagiarism-detection software. There is no gap where plagiarism could squeeze in.
Read moreThanks to our free revisions, there is no way for you to be unsatisfied. We will work on your paper until you are completely happy with the result.
Read moreYour email is safe, as we store it according to international data protection rules. Your bank details are secure, as we use only reliable payment systems.
Read moreBy sending us your money, you buy the service we provide. Check out our terms and conditions if you prefer business talks to be laid out in official language.
Read more