Student’s Name
Institutional Affiliation
One-Way ANOVA
Section 1
Data Context
The grade.sav data set provides a raw data for students’ details regarding their social demographics including gender, ethnicity, year and section of the study, as well as, their performance reflected through the score in quizzes, reviews, and grades for a given subject. For instance, the final grade which determines fail or pass is hypothesized to be influenced by some explanatory variables including the current GPA, a section of the study, the quiz scores, gender, ethnicity and review outcomes. For this analysis, the researcher focuses on n 3determining if the Quiz 3 scores vary across the section of the study of the students.
In other words, the research would investigate if the mean scores for students in different sections are different from each other. In this case, the section that the student is currently in influences the hypothesized scores for the Quiz 3. Accordingly, learning process may be different across these sections hence resulting to differences in scores by the students. Therefore, the section is treated as an explanatory variable while Quiz 3 scores are treated as the dependent outcome or dependent variable. For the analysis, the sample size is depicted as n = 105.
Section 2
Assumptions of a One-Way ANOVA
For a one-factor ANOVA analysis, there are basic assumptions that must be held. Ideally, the variances of the population groups are assumed to be equal, and each group sample is drawn from a population that is normally distributed – the residuals for response variables are approximately normally distributed (Girden, 2002). Again, the samples should be drawn independently indicating that the responses for each given population group are independent, as well as, identically distributed. Lastly, the distributions are assumed not to include any outliers to achieve an F-statistics that well behaves because it is robust to any violation of normality given equal sample sizes and symmetrical populations (Girden, 2002).
Histogram for Quiz 3
Fig. 1
Histogram for Quiz 3
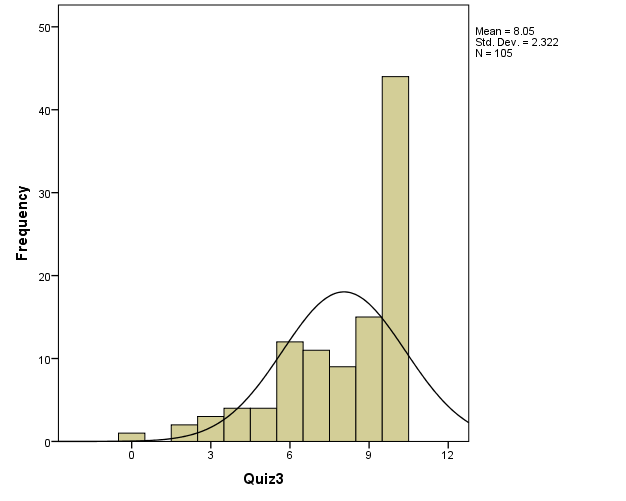
From the above histogram representing the distribution, the mean is given as 8.05 with a standard deviation of 2.322 indicating that the distribution is approximately normal, given that n = 105. Most of the scores are seen to lie within the group mean. However, if the distribution curve is not given and the group means, the data seems to skew to the left. However, such an aspect may be subjected to skewness and Kurtosis or plotting a histogram of the standardized scores for Quiz 3 – which confirms that the data is normal.
Histogram of the standardized scores for Quiz 3

Quiz 3 Descriptive statistics – Skewness and Kurtosis
Table 1
Skewness and Kurtosis for Quiz 3
| Descriptive Statistics | |||||||
| N | Mean | Std. Deviation | Skewness | Kurtosis | |||
| Statistic | Statistic | Statistic | Statistic | Std. Error | Statistic | Std. Error | |
| Quiz3 | 105 | 8.05 | 2.322 | -1.177 | .236 | .805 | .467 |
| Valid N (listwise) | 105 |
The skewness appears to be – 1.177 which shows that the data is slightly skewed to the left. For a normally distributed data, it should be symmetrical and a skewness of -/+ 1. However, if we consider the Kurtosis, which assumes a Gaussian distribution that considers a -/+ 3 variation of the Kurtosis statistics, the data is normal as the statistics are given as 0.805 (lies within the accepted band).
Shapiro-Wilk Test
Table 2
Showing Shapiro-Wilk test for Quiz 3
| Tests of Normality | ||||||
| Kolmogorov-Smirnova | Shapiro-Wilk | |||||
| Statistic | df | Sig. | Statistic | df | Sig. | |
| Quiz3 | .221 | 105 | .000 | .818 | 105 | .000 |
| Lilliefors Significance Correction |
Shapiro-Wilk test tests the idea that the null-hypothesis is drawn from normally distributed population. The test indicates that Shapiro-Wilk statistic is 0.818 and a P-value of 0.000 indicating that the null hypothesis is rejected and concluded that the sample is drawn from a population that is not normally distributed.
Levene’s Test
Table 3
Showing Levene’ Statistic for homogeneity
| Test of Homogeneity of Variances | |||
| Quiz3 | |||
| Levene Statistic | df1 | df2 | Sig. |
| 1.576 | 2 | 102 | .212 |
The Levene’s statistic tests the homogeneity of variances – if population variances are equal. Given that the P-value = 0.212 > 0.05, the null hypothesis is rejected and it can be evidently claimed that there is a difference between group variances. The quiz 3 scores and section variables are independent.
Summary of assumptions
The normal distribution curve and the histogram, the Kurtosis analysis and the Levene’s test confirm that the assumptions of ANOVA are met except normality which from the Shapiro-Wilk test proves that the data is drawn from a distribution that is not normally distributed. However, looking at the assumptions of ANOVA, sample populations are just approximated to have normal residuals that are usually distributed. Hence the ANOVA test can be conducted.
Section 3
Research Question
Are the Quiz 3 cores different across the sections?
Hypothesis statement
H0: The mean scores for quiz 3 are equal across the three sections
H1: The mean scores for quiz 3 are different from the three sections
Alpha
The ANOVA test adopts an alpha of 0.05 indicating that the rejection region would be 0.05 and any P-value lying within this region would lead to rejection of the null hypothesis. Given 95% confidence, does quiz 3 mean scores vary across the three sections?
Section 4
Mean plot for Quiz 3
Fig. 3
Mean plots for Quiz 3 and section
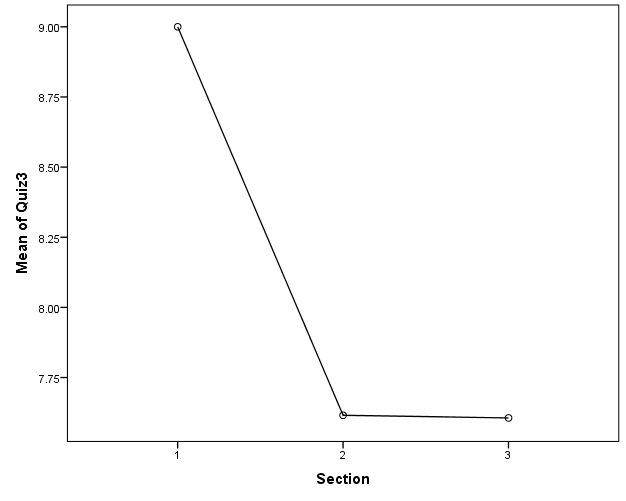
From the mean plots for the Quiz three scores, it is clear that all the group means are different. The group means decreases from section one towards sections 2 and 3. Such an aspect is interesting for running an ANOVA test to see if there is statistical evidence to claim that the group means are different across the three sections.
Descriptive statistics
Table 4
Means and standard deviations for Quiz 3
| Descriptives | ||||||||
| Quiz3 | ||||||||
| N | Mean | Std. Deviation | Std. Error | 95% Confidence Interval for Mean | Minimum | Maximum | ||
| Lower Bound | Upper Bound | |||||||
| 1 | 33 | 9.00 | 2.107 | .367 | 8.25 | 9.75 | 2 | 10 |
| 2 | 39 | 7.62 | 2.098 | .336 | 6.94 | 8.30 | 2 | 10 |
| 3 | 33 | 7.61 | 2.549 | .444 | 6.70 | 8.51 | 0 | 10 |
| Total | 105 | 8.05 | 2.322 | .227 | 7.60 | 8.50 | 0 | 10 |
Table 5
ANOVA test analysis
| ANOVA | |||||
| Quiz3 | |||||
| Sum of Squares | df | Mean Square | F | Sig. | |
| Between Groups | 43.652 | 2 | 21.826 | 4.305 | .016 |
| Within Groups | 517.110 | 102 | 5.070 | ||
| Total | 560.762 | 104 |
Given the ANOVA table above, the F-value is given as 4.305 with 2 degrees of freedom for between groups and 102 degrees of freedom for the within groups. Additionally, the P-value = 0.016 which is less than 0.05 (alpha) indicating that the P-value lies within the rejection region (Field, 2009). Therefore, the null hypothesis is rejected for the alternative hypothesis – indicating that the quiz 3 scores are different across the three sections. From the ANOVA table the Eta-Squared can give the effect size:
Effect size (Eta-Squared) = Sum of Squares (between)/ Sum of squares (Total)
= 43.652 / 560.762
= 0.0778 or 7.78%
The effect size indicates that 7.78% of the total variance is accounted by the treatment effect on the outcome variable (Quiz 3in this case) (Sawilowsky, 2009).
Post-hoc tests
Table 6
Showing Post-hoc tests
| Multiple Comparisons | ||||||
| Dependent Variable: Quiz3 Tukey HSD | ||||||
| (I) Section | (J) Section | Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | |
| Lower Bound | Upper Bound | |||||
| 1 | 2 | 1.385* | .533 | .029 | .12 | 2.65 |
| 3 | 1.394* | .554 | .036 | .08 | 2.71 | |
| 2 | 1 | -1.385* | .533 | .029 | -2.65 | -.12 |
| 3 | .009 | .533 | 1.000 | -1.26 | 1.28 | |
| 3 | 1 | -1.394* | .554 | .036 | -2.71 | -.08 |
| 2 | -.009 | .533 | 1.000 | -1.28 | 1.26 | |
| *. The mean difference is significant at the 0.05 level. |
The post hoc tests are used to identify which groups differ from each other in case the null hypothesis is rejected. Since the data met the homogeneity of variance assumption, the Tukey’s HSD is used to identify which groups differ from each other. Section 1 is statistically different from 2 (P=0.029) and 3 (P=0.036), respectively. However, section 2 is not statistically different from 3 since P = 1.000 > 0.05 (Field, 2009).
Section 5
In conclusion, the study answers the research question; do quiz 3 scores vary across the three sections? Evidently, the scores for quiz 3 are statistically different from the three sections. The study has rejected the null hypothesis that claimed that the scores for quiz 3 are equal. The one-way ANOVA is a strong statistical tool that identifies the mean group differences. Clearly, the post hoc tests indicate that the group means for section 1 is different from sections 2 and 3 while the group means for sections 3 and 2 are not different. Again, the ANOVA test is effective when the predictor variable is a categorical one and has more than two groups. However, one of the main limitation is what has been identified in this study – is assumes data is sampled from a normally distributed population which is not always the case (Donley, 2012). Another assumption that the standard deviation between the groups should be similar holds another limitation – in that the greater the difference in standard deviation, the higher the chance of having inaccurate tests.
References
Field, A. (2009). Discovering statistics using SPSS (3rd ed.). Los Angeles [i.e. Thousand Oaks, Calif.]: SAGE Publications.
Girden, E. R. (2002). ANOVA: Repeated measures. Newbury Park, Calif: Sage Publications.
Donley, A. (2012). Research Methods. New York : Infobase Pub.
Sawilowsky, S (2009). “New effect size rules of thumb.”. Journal of Modern Applied Statistical Methods. 8 (2): 467–474.
Delivering a high-quality product at a reasonable price is not enough anymore.
That’s why we have developed 5 beneficial guarantees that will make your experience with our service enjoyable, easy, and safe.
You have to be 100% sure of the quality of your product to give a money-back guarantee. This describes us perfectly. Make sure that this guarantee is totally transparent.
Read moreEach paper is composed from scratch, according to your instructions. It is then checked by our plagiarism-detection software. There is no gap where plagiarism could squeeze in.
Read moreThanks to our free revisions, there is no way for you to be unsatisfied. We will work on your paper until you are completely happy with the result.
Read moreYour email is safe, as we store it according to international data protection rules. Your bank details are secure, as we use only reliable payment systems.
Read moreBy sending us your money, you buy the service we provide. Check out our terms and conditions if you prefer business talks to be laid out in official language.
Read more